Latest Microsoft DP-100 dumps helpful in getting 100% passing guarantee of the DP-100 exam
Due to the benefits of his career, in the Microsoft DP-100 exam, the difficulty level also remains high. Therefore, the latest DP-100 dump preparation is required to pass the exam in the first attempt. Become a Microsoft Azure Data Scientist Associate with Latest DP-100 dumps by https://www.pass4itsure.com/dp-100.html(Q&As Dumps: 218). Try DP-100 exam dumps pdf free.
dp-100 exam dumps | dp-100 practice test | azure dp-100 dumps | dp-100 dumps | exam dp-100 study guide | dp-100 exam questions

The perfect DP-100 dump learning material, which contains all the necessary information, is the basis for effective preparation for the DP-100 test. If the plan appears in the DP-100 exam, it is recommended that you use Pass4itsure’s DP-100 braindumps.
Use Pass4itsure DP-100 Exam PDF Dumps Preparation Material
Prepared the Microsoft DP-100 dumps pdf [100% free] https://drive.google.com/file/d/1z_1mMhd3fjUYtnlI2_bvw1X3isFSKS5P/view?usp=sharing
Learn With Real Microsoft Azure DP-100 Exam Questions and Answers
In Pass4itsure, you will get 100% correct answers to DP-100 questions, because all answers are verified by experts. With the help of these DP-100 exam questions and answers, you will be able to understand the exam format and all topics of the Microsoft Azure DP-100 exam.
QUESTION 1
You are creating a binary classification by using a two-class logistic regression model. You need to evaluate the model
results for imbalance.
Which evaluation metric should you use?
A. Relative Absolute Error
B. AUC Curve
C. Mean Absolute Error
D. Relative Squared Error
E. Accuracy
F. Root Mean Square Error
Correct Answer: B
One can inspect the true positive rate vs. the false positive rate in the Receiver Operating Characteristic (ROC) curve
and the corresponding Area Under the Curve (AUC) value. The closer this curve is to the upper left corner, the better
the classifier\\’s performance is (that is maximizing the true positive rate while minimizing the false positive rate). Curves
that are close to the diagonal of the plot, result from classifiers that tend to make predictions that are close to random
guessing.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio/evaluate-model-performance#evaluating-abinary-classification-model
QUESTION 2
You are creating a machine learning model.
You need to identify outliers data;
Which two visualizations can you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. box plot
B. scatter
C. random forest diagram
D. Venn diagram
E. ROC curve
Correct Answer: AB
QUESTION 3
You need to correct the model fit issue.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions
to the answer area and arrange them in the correct order.
Select and Place:

Correct Answer:
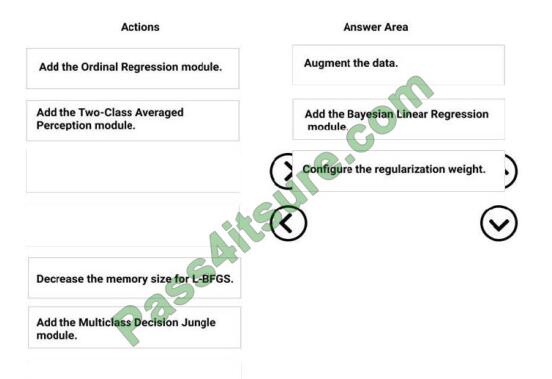
Step 1: Augment the data
Scenario: Columns in each dataset contain missing and null values. The datasets also contain many outliers.
Step 2: Add the Bayesian Linear Regression module.
Scenario: You produce a regression model to predict property prices by using the Linear Regression and Bayesian
Linear Regression modules.
Step 3: Configure the regularization weight.
Regularization typically is used to avoid overfitting. For example, in L2 regularization weight, type the value to use as the
weight for L2 regularization. We recommend that you use a non-zero value to avoid overfitting.
Scenario:
Model fit: The model shows signs of overfitting. You need to produce a more refined regression model that reduces the
overfitting.
Incorrect Answers:
Multiclass Decision Jungle module: Decision jungles are a recent extension to decision forests. A decision jungle consists of an ensemble of decision
directed acyclic graphs (DAGs).
L-BFGS:
L-BFGS stands for “limited memory Broyden-Fletcher-Goldfarb-Shanno”. It can be found in the wwo-Class Logistic
Regression module, which is used to create a logistic regression model that can be used to predict two (and only two)
outcomes.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/linear-regression
QUESTION 4
You need to configure the Feature Based Feature Selection module based on the experiment requirements and
datasets.
How should you configure the module properties? To answer, select the appropriate options in the dialog box in the
answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
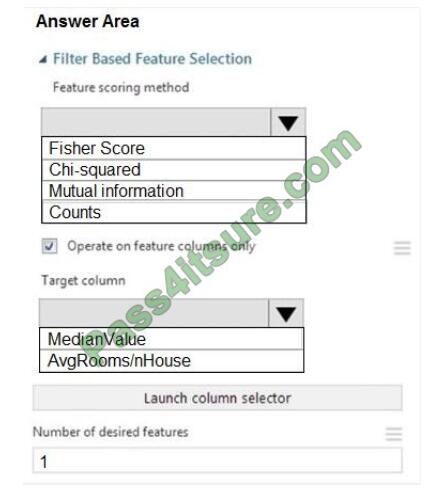
Correct Answer:
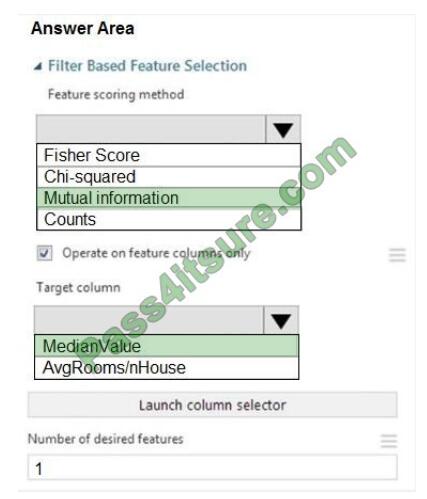
Box 1: Mutual Information.
The mutual information score is particularly useful in feature selection because it maximizes the mutual information
between the joint distribution and target variables in datasets with many dimensions.
Box 2: MedianValue
MedianValue is the feature column, , it is the predictor of the dataset.
Scenario: The MedianValue and AvgRoomsinHouse columns both hold data in numeric format. You need to select a
feature selection algorithm to analyze the relationship between the two columns in more detail.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/filter-based-feature-selection
QUESTION 5
HOTSPOT
You are developing a machine learning, experiment by using Azure. The following images show the input and output of
a machine learning experiment:
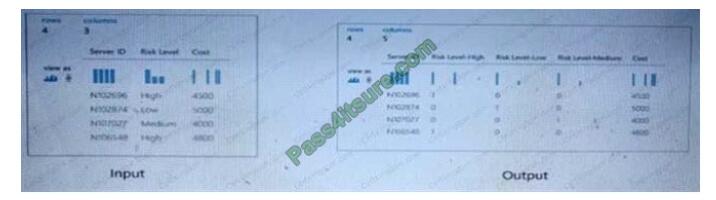
Use the drop-down menus to select the answer choice that answers each question based on the information presented
in the graphic. NOTE: Each correct selection is worth one point.
Hot Area:

QUESTION 6
You plan to deliver a hands-on workshop to several students. The workshop will focus on creating data visualizations
using Python. Each student will use a device that has internet access.
Student devices are not configured for Python development. Students do not have administrator access to install
software on their devices. Azure subscriptions are not available for students.
You need to ensure that students can run Python-based data visualization code.
Which Azure tool should you use?
A. Anaconda Data Science Platform
B. Azure BatchAl
C. Azure Notebooks
D. Azure Machine Learning Service
Correct Answer: C
References: https://notebooks.azure.com/
QUESTION 7
You need to select a pre built development environment for a series of data science experiments. You must use the R
language for the experiments.
Which three environments can you use? Each correct answer presents a complete solution. NOTE:
Each correct selection is worth one point.
A. MI.NET Library on a local environment
B. Azure Machine Learning Studio
C. Data Science Virtual Machine (OSVM)
D. Azure Data bricks
E. Azure Cognitive Services
Correct Answer: ABD
QUESTION 8
You need to select a feature extraction method. Which method should you use?
A. Mutual information
B. Pearson\\’s correlation
C. Spearman correlation
D. Fisher Linear Discriminant Analysis
Correct Answer: C
Spearman\\’s rank correlation coefficient assesses how well the relationship between two variables can be described
using a monotonic function.
Note: Both Spearman\\’s and Kendall\\’s can be formulated as special cases of a more general correlation coefficient,
and they are both appropriate in this scenario.
Scenario: The MedianValue and AvgRoomsInHouse columns both hold data in numeric format. You need to select a
feature selection algorithm to analyze the relationship between the two columns in more detail.
Incorrect Answers:
B: The Spearman correlation between two variables is equal to the Pearson correlation between the rank values of
those two variables; while Pearson\\’s correlation assesses linear relationships, Spearman\\’s correlation assesses
monotonic relationships (whether linear or not).
QUESTION 9
DRAG DROP
You need to visually identify whether outliers exist in the Age column and quantify the outliers before the outliers are
removed.
Which three Azure Machine Learning Studio modules should you use in sequence? To answer, move the appropriate
modules from the list of modules to the answer area and arrange them in the correct order.
Select and Place:
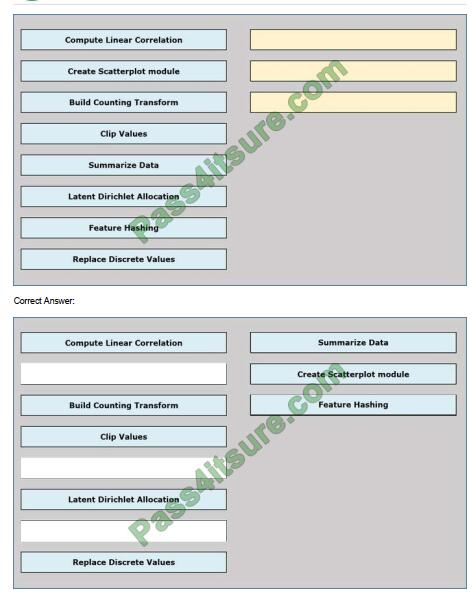
QUESTION 10
You need to select a feature extraction method. Which method should you use?
A. Mutual information
B. Mood\\’s median test
C. Kendall correlation
D. Permutation Feature Importance
Correct Answer: C
In statistics, the Kendall rank correlation coefficient, commonly referred to as Kendall\\’s tau coefficient (after the Greek
letter ), is a statistic used to measure the ordinal association between two measured quantities. It is a supported method
of the Azure Machine Learning Feature selection.
Scenario: When you train a Linear Regression module using a property dataset that shows data for property prices for a
large city, you need to determine the best features to use in a model. You can choose standard metrics provided to
measure performance before and after the feature importance process completes. You must ensure that the distribution
of the features across multiple training models is consistent.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/feature-selectionmodules
QUESTION 11
You are performing a filter-based feature selection for a dataset to build a multi-class classifier by using Azure Machine
Learning Studio.
The dataset contains categorical features that are highly correlated to the output label column.
You need to select the appropriate feature scoring statistical method to identify the key predictors.
Which method should you use?
A. Chi-squared
B. Spearman correlation
C. Kendall correlation
D. Pearson correlation
Correct Answer: D
Pearson\\’s correlation statistic, or Pearson\\’s correlation coefficient, is also known in statistical models as the r value.
For any two variables, it returns a value that indicates the strength of the correlation
Pearson\\’s correlation coefficient is the test statistics that measures the statistical relationship, or association, between
two continuous variables. It is known as the best method of measuring the association between variables of interest because it is based on the method of covariance. It gives information about the magnitude of the association, or
correlation, as well as the direction of the relationship.
Incorrect Answers:
C: The two-way chi-squared test is a statistical method that measures how close expected values are to actual results.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/filter-based-featureselection https://www.statisticssolutions.com/pearsons-correlation-coefficient/
QUESTION 12
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
You are analyzing a numerical dataset which contain missing values in several columns.
You must clean the missing values using an appropriate operation without affecting the dimensionality of the feature
set.
You need to analyze a full dataset to include all values.
Solution: Use the last Observation Carried Forward (IOCF) method to impute the missing data points.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: B
QUESTION 13
You must store data in Azure Blob Storage to support Azure Machine Learning.
You need to transfer the data into Azure Blob Storage.
What are three possible ways to achieve the goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Bulk Insert SQL Query
B. AzCopy
C. Python script
D. Azure Storage Explorer
E. Bulk Copy Program (BCP)
Correct Answer: BCD
You can move data to and from Azure Blob storage using different technologies:
1.
Azure Storage-Explorer
2.
AzCopy
3.
Python
4.
SSIS
References: https://docs.microsoft.com/en-us/azure/machine-learning/team-data-science-process/move-azure-blob
Click here to get practice questions for other Microsoft exams.
Get Free Updates for 365 Days on DP-100 Dumps 2020
If you want to successfully take the DP-100 exam, you must prepare according to the latest DP-100 dump preparation materials. Always keep the answers to the questions in the DP-100 question dumps updated. Provide updates within 365 days after purchase.
Get Special Discount Offer on DP-100 Dumps
Latest discount code “2020PASS“, Pass4itsure is giving up to a 12% discount on the DP-100 exam dumps.

P.S
If you have accurate and useful study materials, you can get the best results from the DP-100 exam. You can get the best results by following the above methods. Latest Microsoft DP-100 dumps – https://www.pass4itsure.com/dp-100.html 100% passing guarantee of the DP-100 exam.
dp-100 exam dumps | dp-100 practice test | azure dp-100 dumps | dp-100 dumps | exam dp-100 study guide | dp-100 exam questions